Redis常见面试题总结
本文最后更新于 2025-07-18,文章内容可能已经过时。
一、Redis基础
1.说一下Redis和Memcached的区别和共同点
共同点:
都是基于内存的数据库,一般都用来当做缓存使用。
都有过期策略。
两者的性能都非常高。
区别:
数据类型:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
数据持久化:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
集群模式支持:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
线程模型:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
特性支持:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
过期数据删除:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
二、Redis应用
1.Redis除了做缓存,还能做什么?
分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:分布式锁详解。
限流:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
分布式 Session:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
2.Redis是如何判断数据是否过期的呢?
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
3.Reids过期key删除策略了解么?
常用的过期数据的删除策略就下面这几种:
惰性删除:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
定期删除:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
延迟队列:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
定时删除:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
4.Redis内存淘汰策略了解吗?
Redis 的内存淘汰策略只有在运行内存达到了配置的最大内存阈值时才会触发,这个阈值是通过 redis.conf 的 maxmemory 参数来定义的。64 位操作系统下,maxmemory 默认为 0,表示不限制内存大小。32 位操作系统下,默认的最大内存值是 3GB。
Redis 提供了 6 种内存淘汰策略:
volatile-lru(least recently used):从已设置过期时间的数据集(
server.db[i].expires)中挑选最近最少使用的数据淘汰。volatile-ttl:从已设置过期时间的数据集(
server.db[i].expires)中挑选将要过期的数据淘汰。volatile-random:从已设置过期时间的数据集(
server.db[i].expires)中任意选择数据淘汰。allkeys-lru(least recently used):从数据集(
server.db[i].dict)中移除最近最少使用的数据淘汰。allkeys-random:从数据集(
server.db[i].dict)中任意选择数据淘汰。no-eviction(默认内存淘汰策略):禁止驱逐数据,当内存不足以容纳新写入数据时,新写入操作会报错。
volatile-lfu(least frequently used):从已设置过期时间的数据集(
server.db[i].expires)中挑选最不经常使用的数据淘汰。allkeys-lfu(least frequently used):从数据集(
server.db[i].dict)中移除最不经常使用的数据淘汰。
allkeys-xxx 表示从所有的键值中淘汰数据,而 volatile-xxx 表示从设置了过期时间的键值中淘汰数据。
三、Redis生成问题
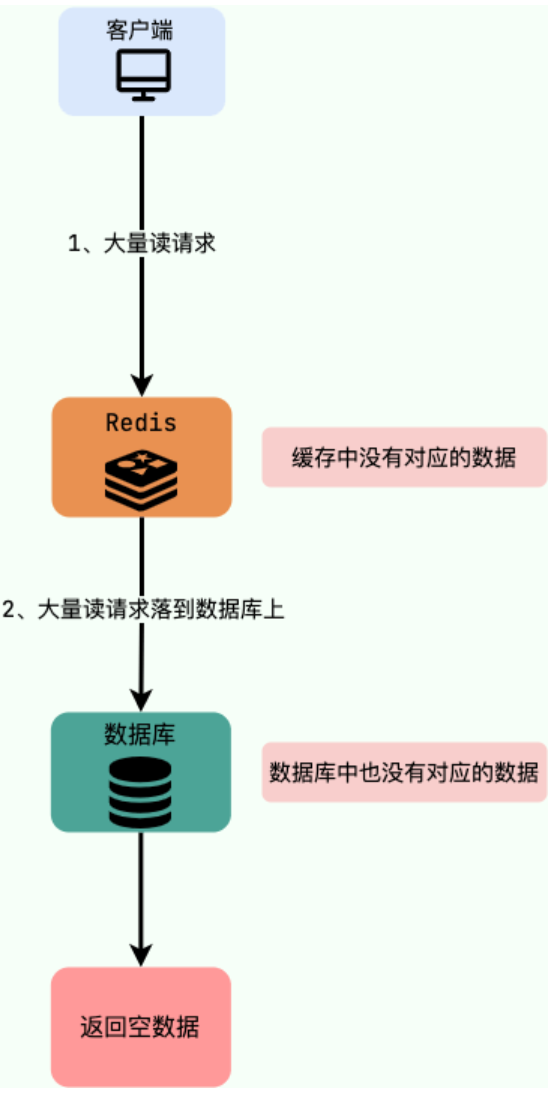
1.什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
有哪些解决办法?
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
2.什么是缓存击穿?
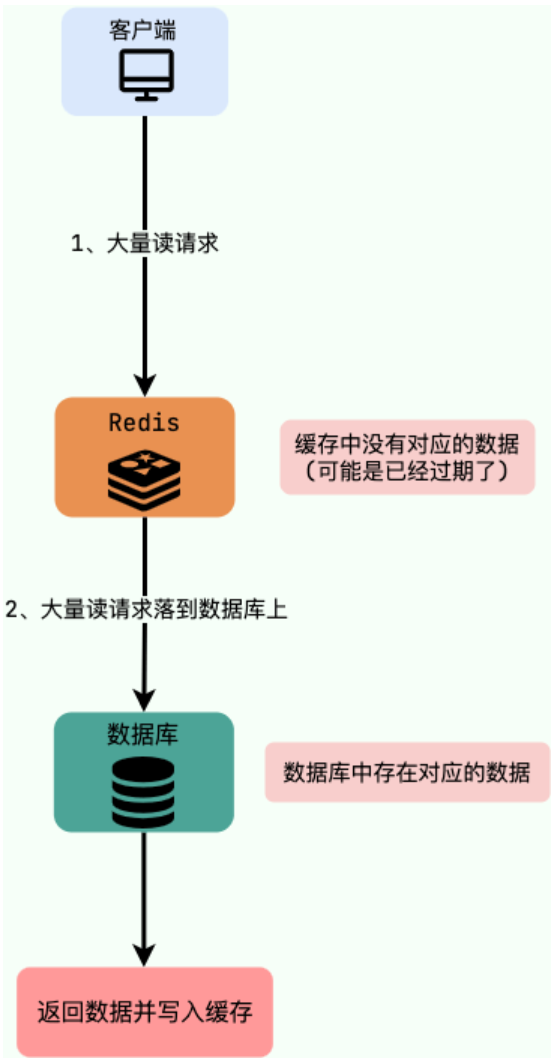
缓存击穿中,请求的 key 对应的是 热点数据,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
有哪些解决办法?
永不过期(不推荐):设置热点数据永不过期或者过期时间比较长。
提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
加锁(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
缓存穿透和缓存击穿有什么区别?
缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。
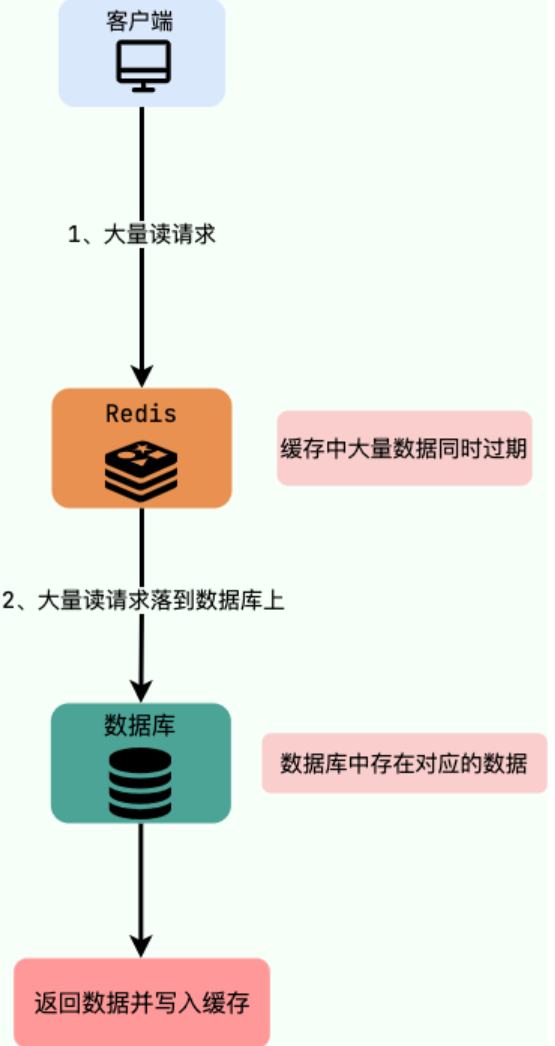
3.什么是缓存雪崩?
实际上,缓存雪崩描述的就是这样一个简单的场景:缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。
针对大量缓存同时失效的情况:
设置随机失效时间(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间,比如秒杀场景下的数据在秒杀结束之前不过期。
持久缓存策略(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。
缓存雪崩和缓存击穿有什么区别?
缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在于缓存中(通常是因为缓存中的那份数据已经过期)。
